
D'où les IA tirent-elles leurs infos ? Le top 10 des sources les plus citées
Les intelligences artificielles nous impressionnent par leurs connaissances, mais d'où tirent-elles leurs informations ? Une étude réalisée par Statista et Semrush en juin 2025 révèle le top 10 des sources les plus citées par les grands modèles de langage (LLMs). Les résultats sont surprenants : Reddit occupe la première place, devant Wikipédia et YouTube. Un classement qui soulève des questions fondamentales sur la fiabilité, les biais et la diversité des sources utilisées par les IA.
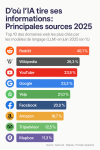
Le top 10 des sources les plus citées par les IA
Selon l'étude menée sur 150 000 citations issues de 5 000 mots-clés aléatoires, voici le classement des domaines web les plus fréquemment cités par les LLMs comme ChatGPT, Google AI Mode ou Perplexity :
| Source | Secteur | Pourcentage de citations |
|---|---|---|
| Réseaux sociaux / Forum communautaire | 40,11% | |
| Wikipédia | Encyclopédie en ligne / Base de connaissances | 26,33% |
| YouTube | Plateforme vidéo / Contenu multimédia | 23,52% |
| Moteur de recherche / Services web | 23,28% | |
| Yelp | Avis et recommandations locales | 21,01% |
| Réseaux sociaux | 19,96% | |
| Amazon | E-commerce / Vente en ligne | 18,72% |
| TripAdvisor | Avis voyage / Tourisme | 12,46% |
| Mapbox | Cartographie / Services géolocalisation | 11,29% |
| OpenStreetMap | Cartographie collaborative | 11,29% |
Ce classement révèle une prédominance écrasante des plateformes communautaires et des géants du web, au détriment des sources traditionnellement considérées comme fiables comme les publications scientifiques ou les médias d'information.
Méthodologie : comment ces données ont été collectées ?
L'étude, réalisée par Semrush et publiée sur Statista, s'appuie sur une analyse rigoureuse :
- Période : premier trimestre 2025
- Portée : mondiale
- Modèles analysés : Google AI Mode, AI Overviews, ChatGPT et Perplexity
- Méthode : analyse de 150 000 citations issues de 5 000 mots-clés aléatoires
Cette approche permet d'avoir une vision représentative des sources utilisées par les principaux LLMs du marché. Les résultats mettent en lumière une dépendance massive à quelques plateformes, avec Reddit qui dépasse largement tous les autres domaines web. Ce n'est pas une étude légère, c'est un travail statistiques approfondit qui s'appuie sur l'expertise reconnue de Semrush (une plateforme connue dans le domaine du SEO ).
Pourquoi Reddit domine-t-il si largement ?
La première place de Reddit (40,11% des citations) s'explique par plusieurs facteurs clés :
- L'accord de licence avec Google : signé début 2024, il permet à Google d'utiliser l'ensemble des discussions publiques de Reddit pour entraîner ses modèles d'IA.
- Le volume de contenu : Reddit génère une quantité massive de textes en langage naturel, bien supérieure à celle de Wikipédia.
- La diversité des sujets : chaque subreddit est dédié à un thème précis, offrant aux IA un accès à des informations spécialisées.
- Le format conversationnel : les échanges sur Reddit ressemblent aux questions/réponses que les IA sont entraînées à générer.
Le paradoxe de la fiabilité
Cette domination de Reddit pose pourtant question. Contrairement à Wikipédia, qui dispose d'un système de vérification et de modération, Reddit repose sur des discussions entre utilisateurs de tous horizons, sans validation systématique des informations.
Les contributions ne sont pas soumises à relecture par les pairs, et les contenus peuvent être erronés, partiaux, ou trompeurs. Pourtant, ce sont ces échanges qui nourrissent majoritairement les IA actuelles.
Wikipédia : une source plus fiable mais moins citée
Wikipédia arrive en deuxième position avec 26,33% des citations. Cette plateforme présente plusieurs avantages en termes de fiabilité :
- Principes éditoriaux stricts : sources secondaires vérifiables, neutralité, surveillance communautaire
- Contributions régulières : souvent rédigées par des contributeurs avec des connaissances solides
- Modifications tracées : possibilité de suivre l'évolution des articles et de révertir les modifications problématiques
Malgré cette rigueur, Wikipédia est moins citée que Reddit, principalement à cause d'un volume de contenu moindre et d'un style plus formel, moins adapté pour générer des réponses conversationnelles.
Où sont passées les sources scientifiques ?
L'absence des publications scientifiques comme Nature, Science ou The Lancet dans le top 10 est révélatrice d'un problème plus profond. Plusieurs facteurs expliquent cette sous-représentation :
- Accès restreint : la plupart des articles scientifiques sont payants ou derrière des paywalls, limitant leur accessibilité pour l'entrainement des IA
- Format complexe : les articles sont très techniques, longs et spécialisés, peu adaptés à des résumés généraux
- Volume faible : même en cumulant toutes les publications scientifiques ouvertes, cela reste infime comparé aux milliards de discussions Reddit
- Langage formel : le style académique est éloigné des échanges naturels, le rendant moins utile pour entraîner des modèles conversationnels
Les biais des LLMs : un miroir du web, pas de la vérité
Ce classement révèle un problème fondamental : les LLMs n’évaluent pas la fiabilité des sources. Ils reproduisent simplement ce qu’ils ont le plus lu. Cela crée plusieurs biais.
D’abord, un biais de popularité : les plateformes visibles comme Reddit ou Wikipédia sont surreprésentées. Ensuite, un biais de contenu : les savoirs pratiques l’emportent sur les connaissances académiques.
Puis un risque de désinformation : les erreurs de Reddit peuvent être amplifiées par les IA. Enfin, un angle occidental : la domination des sites anglophones favorise un point de vue occidental dans les réponses.
Vers une amélioration de la qualité des sources ?
Face à ces limites, plusieurs initiatives émergent pour améliorer la qualité des sources utilisées par les IA :
- Développement de modèles spécialisés dans l'exploitation de la littérature scientifique ouverte (comme Elicit ou Semantic Scholar)
- Recherches sur des méthodes pour "pondérer" les sources selon leur fiabilité plutôt que leur volume
- Intégration de mécanismes de vérification des faits dans les réponses générées par les IA
Ces avancées sont essentielles pour passer d'un modèle qui "copie" le web à un modèle qui "comprend" et "hiérarchise" les savoirs.
Un reflet de nos usages quotidiens plus qu'un choix technique ?
Ce top 10 ne reflète pas seulement les biais des IA, mais aussi la nature des questions que nous leur posons. Les utilisateurs interrogent principalement les LLMs sur des sujets pratiques : avis de voyage, recommandations produits, solutions du quotidien, ou centres d’intérêt variés.
Ces requêtes trouvent naturellement leurs réponses sur des plateformes comme Reddit, où les expériences concrètes et les discussions communautaires abondent. Ainsi, la surreprésentation de Reddit n’est pas seulement un biais technique – elle est aussi le miroir de nos usages quotidiens. Les IA puisent prioritairement dans les sources qui répondent le mieux aux besoins réels et fréquents des utilisateurs.
Conclusion : un enjeu majeur pour l'avenir de l'IA
Le classement des sources les plus citées par les IA révèle une dépendance préoccupante à quelques plateformes communautaires, au détriment de sources plus fiables et diversifiées. Cette situation soulève des questions fondamentales sur la qualité, la fiabilité et la diversité des informations fournies par les intelligences artificielles.
Alors que les IA deviennent des outils incontournables pour accéder à l'information, il est crucial de développer des mécanismes garantissant une meilleure représentation des sources de qualité. L'avenir de l'IA dépendra de sa capacité à dépasser les simples statistiques de fréquence pour intégrer une véritable compréhension de la fiabilité des sources.
Sources
- Top web domains cited by LLMs 2025 - Statista
Étude complète réalisée par Statista et Semrush sur les sources les plus citées par les LLMs en juin 2025. - Reddit tops AI information top sources list in 2025, outpacing Google and Wikipedia - Storyboard18
Analyse des résultats de l'étude et leurs implications. - Where AI gets it's info — Top web domains cited by large language models - Reddit
Discussion communautaire sur les résultats de l'étude.
Quelle est la source d'information la plus citée par les IA en 2025 ?
Reddit est la source la plus citée par les IA en 2025, avec 40,11% des citations, selon une étude Statista et Semrush. Cette domination s'explique principalement par l'accord de licence entre Reddit et Google, le volume massif de contenu et le format conversationnel des échanges sur la plateforme.
Pourquoi Wikipédia est-elle moins citée que Reddit par les IA ?
Bien que plus fiable, Wikipédia est moins citée (26,33%) que Reddit principalement à cause de son volume de contenu moindre et de son style plus formel et encyclopédique, moins adapté pour entraîner des IA à générer des réponses conversationnelles.
Les publications scientifiques sont-elles utilisées par les IA ?
Les publications scientifiques comme Nature ou Science sont quasiment absentes du top 10 des sources citées par les IA. Cette sous-représentation s'explique par leur accès souvent payant, leur format complexe et technique, leur volume faible comparé aux discussions Reddit, et leur langage très formel.
Quels sont les risques liés à la dépendance des IA à Reddit ?
La dépendance des IA à Reddit présente plusieurs risques : biais d'information due au manque de vérification, amplification des erreurs ou désinformation, surreprésentation des opinions populaires plutôt que des faits vérifiés, et angle occidental dans les réponses générées.
Comment améliorer la qualité des sources utilisées par les IA ?
Plusieurs pistes existent pour améliorer la qualité des sources des IA : développer des modèles spécialisés dans les sources scientifiques, créer des systèmes de pondération selon la fiabilité plutôt que le volume, intégrer des mécanismes de vérification des faits, et diversifier les sources pour réduire les biais.




