
Reinforcement Learning : comment cette technique révolutionne les IA modernes
L'intelligence artificielle ne cesse d'évoluer, et au cœur de cette transformation se trouve une technique aussi puissante que méconnue : le reinforcement learning. Longtemps cantonné aux jeux vidéo et à la robotique, ce domaine d'apprentissage automatique s'est aujourd'hui imposé comme un pilier des IA contemporaines. Mais comment fonctionne réellement cette approche qui permet aux machines d'apprendre par elles-mêmes ? Et surtout, quels résultats concrets a-t-elle déjà permis d'obtenir, des victoires stratégiques d'AlphaGo aux améliorations tangibles de ChatGPT ?
Le Reinforcement Learning : principes fondamentaux
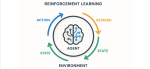
Le reinforcement learning (RL) est une branche du machine learning où un agent apprend à prendre des décisions en interagissant avec un environnement. Contrairement à l'apprentissage supervisé classique, l'agent n'a pas accès à un jeu de données étiquetées. Il apprend plutôt par essais et erreurs, en recevant des récompenses ou des pénalités selon ses actions.
Le processus repose sur cinq éléments clés :
- L'agent : l'entité qui apprend et prend des décisions
- L'environnement : le monde avec lequel l'agent interagit
- L'état : la représentation complète des informations pertinentes de l'environnement à un moment précis, contenant tout ce dont l'agent a besoin pour prendre des décisions optimales (par exemple : positions des pièces aux échecs, position et vitesse d'un véhicule, configuration d'un centre de données...)
- Les actions : ce que l'agent peut faire dans l'environnement
- Les récompenses : les signaux qui indiquent à l'agent si ses actions sont bonnes ou mauvaises
L'objectif est simple : maximiser la récompense cumulée sur le long terme. Cette approche s'inspire des mécanismes d'apprentissage naturel, mais avec une efficacité qui, dans certains domaines spécifiques, dépasse les performances humaines.
AlphaGo Zero : un cas d'étude significatif
L'un des exemples les plus documentés de l'application du RL est AlphaGo Zero, développé par DeepMind. Contrairement à son prédécesseur qui apprenait à partir de parties humaines, AlphaGo Zero a appris uniquement en jouant contre lui-même, sans connaissance préalable des stratégies humaines.
Les résultats observés sont notables : après environ 40 jours d'auto-entraînement, AlphaGo Zero a battu la version précédente d'AlphaGo (qui avait déjà vaincu le champion du monde Lee Sedol) avec un score de 100-0. Cette performance démontre la capacité du RL à découvrir des stratégies qui diffèrent de l'expertise humaine traditionnelle.
Un aspect technique important : AlphaGo Zero a atteint ce niveau de performance en étant 100 fois plus efficace en termes de calcul que la version précédente, illustrant le potentiel d'optimisation offert par cette approche.
Le RL dans les IA modernes : une intégration progressive
Si le RL s'est d'abord distingué dans les domaines ludiques, son application s'est étendue à d'autres secteurs. Aujourd'hui, il contribue au fonctionnement de nombreuses IA contemporaines, parfois de manière peu visible pour l'utilisateur final.
L'une des applications les plus répandues est le RLHF (Reinforcement Learning from Human Feedback), utilisé pour affiner des modèles de langage comme ChatGPT. Après un pré-entraînement supervisé, ces modèles sont optimisés grâce au RL où des humains évaluent leurs réponses. L'IA apprend alors à générer des réponses plus pertinentes, plus sûres et mieux alignées avec les attentes humaines.
RLHF : améliorations quantitatives dans les LLM
Le RLHF ne se limite pas à améliorer la perception subjective des utilisateurs. L'étude publiée par OpenAI en 2022 "Training language models to follow instructions with human feedback" met en évidence des progrès mesurables dans plusieurs dimensions concernant son modèle InstructGPT (InstructGPT est la famille de modèles développés par OpenAI en appliquant précisément la technique RLHF à GPT-3).
- Véracité et fiabilité : Sur le benchmark TruthfulQA, InstructGPT génère des réponses véridiques et informatives environ deux fois plus fréquemment que GPT-3. Le taux d'hallucination (génération d'informations non fondées) passe de 41% avec GPT-3 à 21% avec InstructGPT.
- Sécurité : InstructGPT produit environ 25% moins de sorties toxiques que GPT-3 lorsqu'on lui demande d'être respectueux, une réduction significative pour le déploiement responsable de ces technologies.
Ces mesures indiquent que le RLHF représente une avancée technique substantielle qui contribue à rendre les IA plus fiables et plus alignées avec les valeurs humaines.
Applications concrètes
Au-delà des modèles de langage, le RL s'applique à divers secteurs avec des résultats quantifiables.
Dans le domaine de la robotique, une étude parue sur Quantum Zeitgeist en 2024 illustre de manière spectaculaire les avancées permises par le framework SimpleVLA-RL. Cette approche innovante combine trois éléments clés : la perception visuelle, la compréhension d'instructions en langage naturel et l'exécution d'actions physiques, permettant aux robots de s'attaquer à des tâches complexes avec une efficacité remarquable.
La performance la plus frappante de cette recherche réside dans sa capacité à obtenir des résultats exceptionnels à partir d'un minimum d'exemples. Lorsqu'un humain démontre une tâche une seule fois au robot, le système d'apprentissage par renforcement parvient à améliorer radicalement ses performances sur le benchmark LIBERO-Long – un test standard évaluant la capacité de généralisation sur des tâches prolongées. Le taux de réussite passe ainsi de 17.1% à 91.7%, soit une progression spectaculaire de plus de 70 points.
Dans le domaine des véhicules autonomes, une recherche publiée sur ResearchGate illustre l'efficacité du Q-learning, un algorithme fondamental d'apprentissage par renforcement. Après 2340 minutes d'entraînement en simulation, le modèle a atteint une vitesse moyenne de 94 km/h, se rapprochant de la vitesse maximale de 110 km/h. Cette performance démontre que le véhicule a développé une politique de contrôle complexe équilibrant sécurité et efficacité, optimisant simultanément sa trajectoire, sa vitesse et ses interactions avec l'environnement. Ce résultat souligne la capacité du RL à permettre aux systèmes autonomes d'acquérir rapidement des comportements sophistiqués sans programmation explicite exhaustive.
Enfin, concernant l'optimisation énergétique, une revue publiée dans Applied Energy (Kahil et al., 2025) indique que le RL peut réduire la consommation d'énergie des centres de données de 15% à 40% en optimisant dynamiquement les systèmes de refroidissement et la répartition des charges de travail.
Les défis techniques du RL dans les IA modernes
Malgré ses avancées, le RL fait face à plusieurs défis techniques importants dans son intégration aux IA contemporaines :
- L'efficacité échantillonnale : le RL nécessite souvent un grand nombre d'interactions avec l'environnement pour apprendre efficacement. Dans le contexte des LLM, cela se traduit par des besoins importants en données d'évaluation humaine. Par exemple, l'entraînement d'InstructGPT a requis des dizaines de milliers de comparaisons humaines.
- La stabilité de l'entraînement : les algorithmes de RL peuvent présenter des difficultés de convergence, surtout lorsqu'ils sont combinés avec des réseaux de neurones profonds. Des techniques comme le PPO (Proximal Policy Optimization) ont été développées pour améliorer cette stabilité.
- L'équilibre exploration-exploitation : trouver le compromis approprié entre l'essai de nouvelles actions et l'utilisation de celles connues comme efficaces reste un défi technique et théorique, particulièrement dans des environnements complexes.
Perspectives d'évolution du RL
Le domaine de l'apprentissage par renforcement (RL) connaît un essor dynamique, porté par plusieurs axes de recherche prometteurs qui pourraient façonner l'IA de demain.
Parmi eux, le RL multi-agents prend de l'ampleur : il implique plusieurs agents apprenant simultanément, en coopération ou en compétition. Cette approche s'avère particulièrement pertinente pour modéliser des systèmes complexes comme les marchés financiers ou les interactions sociales.
Parallèlement, l'apprentissage par renforcement inverse (Inverse RL) offre une nouvelle perspective. Plutôt que de recevoir des récompenses explicites, l'agent y déduit les objectifs d'un expert en observant son comportement, ouvrant la voie à une compréhension plus fine des intentions humaines.
Enfin, le méta-apprentissage par renforcement vise à doter les agents d'une capacité d'adaptation rapide, leur permettant d'acquérir de nouvelles compétences avec peu d'expérience. Cette piste pourrait permettre aux IA de généraliser efficacement à partir d'exemples limités, comme l'illustre l'expérience SimpleVLA-RL en robotique.
Sources
- Mastering the Game of Go without Human Knowledge - Silver et al., Nature 2017 : Article original décrivant comment AlphaGo Zero a atteint un score de 100-0 contre la version précédente d'AlphaGo.
- Training language models to follow instructions with human feedback - Ouyang et al., arXiv 2022 : Étude montrant que les modèles InstructGPT sont préférés 85% du temps par rapport à GPT-3, avec des réductions significatives des hallucinations (21% vs 41%) et de la toxicité (-25%).
- Reinforcement Learning Scales Vision-Action Skills - Quantum Zeitgeist 2024 : Article décrivant comment le RL a amélioré les taux de réussite en robotique de 17.1% à 91.7% avec une seule démonstration par tâche.
- Analysis of Reinforcement Learning in Autonomous Vehicles - ResearchGate : Étude montrant qu'un modèle RL a atteint une vitesse moyenne de 94 km/h après 2340 minutes d'entraînement en simulation de conduite autonome.
Qu'est-ce que le reinforcement learning ?
Le reinforcement learning (ou apprentissage par renforcement) est une méthode d'apprentissage automatique où un agent apprend à prendre des décisions en interagissant avec un environnement. Il reçoit des récompenses pour les actions appropriées et des pénalités pour les inappropriées, apprenant ainsi à maximiser ses récompenses cumulées sur le long terme.
Comment le RL est-il utilisé dans les IA comme ChatGPT ?
Dans les modèles de langage comme ChatGPT, le RL est principalement utilisé via la technique RLHF (Reinforcement Learning from Human Feedback). Après un pré-entraînement supervisé, des humains évaluent les réponses du modèle, et un algorithme de RL optimise le modèle pour générer des réponses mieux alignées avec les préférences humaines.
Quelles sont les applications concrètes du reinforcement learning ?
Le RL est appliqué dans plusieurs domaines avec des résultats mesurables : robotique (taux de réussite passant de 17.1% à 91.7%), véhicules autonomes (atteinte de 94 km/h en moyenne après apprentissage), optimisation énergétique des centres de données (réductions de 15-40%), jeux (AlphaGo Zero battant 100-0 son prédécesseur), et modèles de langage (réduction de 50% des hallucinations et 25% de toxicité).
Quels sont les principaux défis du reinforcement learning ?
Les principaux défis du RL incluent : l'efficacité échantillonnale (nécessité de nombreuses interactions pour apprendre), la stabilité de l'entraînement (difficultés de convergence avec les réseaux profonds), l'équilibre exploration-exploitation (trouver le compromis entre essai de nouvelles actions et utilisation des actions connues), et la définition de récompenses appropriées pour guider l'apprentissage.
Quelles sont les perspectives d'avenir pour le reinforcement learning ?
Les orientations de recherche en RL incluent : le RL multi-agents (plusieurs agents apprenant simultanément), l'apprentissage par renforcement inverse (inférence des objectifs par observation), le méta-apprentissage par renforcement (agents capables d'apprendre rapidement), et l'intégration accrue du RL dans les systèmes d'IA généraux pour résoudre des problèmes complexes de manière autonome.





