
L'architecture "Mixture of Experts" (MoE) expliquée simplement
Dans le paysage de l'intelligence artificielle, une architecture gagne en popularité : le Mixture of Experts (MoE). Cette approche révolutionnaire permet de créer des modèles à la fois puissants et efficaces. Mais comment fonctionne-t-elle exactement ? Pourquoi des modèles comme Mixtral ou GPT-4 l'adoptent-ils ? Décryptons ensemble cette innovation devenue incontournable pour le deep learning.
Qu'est-ce que le Mixture of Experts (MoE) ?
Le Mixture of Experts est une architecture d'intelligence artificielle qui divise le travail entre plusieurs "experts" spécialisés. Imaginez une équipe de spécialistes où chaque membre excelle dans un domaine précis. Plutôt que de mobiliser tous les experts pour chaque tâche, un système de routage sélectionne uniquement les plus pertinents.
Cette approche permet de créer des modèles d'IA très puissants sans nécessiter une puissance de calcul démesurée. Concrètement, un modèle MoE peut contenir l'équivalent de centaines de milliards de "briques de connaissance" (ce qu'on appelle des paramètres), mais n'en utilise qu'une petite partie pour répondre à chaque question. C'est comme si une immense bibliothèque n'ouvrait que les quelques livres pertinents pour votre recherche, plutôt que de tout parcourir à chaque fois.
Les origines du Mixture of Experts
Le concept de MoE n'est pas nouveau. Il trouve ses racines dans les années 1990, où il était initialement utilisé pour des problèmes d'apprentissage statistique. Cependant, son application à grande échelle dans le deep learning ne s'est répandue que récemment, grâce à :
- L'augmentation de la puissance de calcul
- Les avancées en matière de parallélisation
- La nécessité de modèles plus performants
Des entreprises comme Google et Meta ont largement contribué à populariser cette architecture dans leurs recherches.
Comment fonctionne l'architecture MoE ?
L'architecture MoE repose sur trois composants clés :
1. Les experts : Ce sont des sous-réseaux neuronaux indépendants, chacun spécialisé dans certains types de données ou tâches.
2. Le réseau de routage (gating network) : C'est le "chef d'orchestre" qui analyse l'entrée et détermine quels experts sont les plus compétents pour traiter la requête.
3. Le mécanisme de combinaison : Une fois les experts sélectionnés, leurs sorties sont agrégées pour produire la réponse finale.
L'innovation majeure réside dans le fait que seuls quelques experts sont activés pour chaque entrée, généralement 2 à 4, même si le modèle en compte des dizaines ou des centaines.
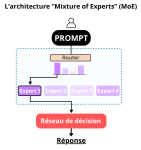
Le processus de routage : le cœur du système
Le routage est l'élément le plus critique d'une architecture MoE. Il doit répondre à deux questions :
- Quels experts activer pour cette entrée ?
- Quel poids accorder à chaque expert sélectionné ?
Les algorithmes de routage modernes fonctionnent comme un chef d'orchestre qui sait quels musiciens faire jouer pour chaque morceau. Ils analysent rapidement la question posée et attribuent un "score de pertinence" à chaque expert, comme si on notait chaque spécialiste sur sa capacité à répondre.
Le défi du routage est double : il doit être rapide (ne pas perdre de temps à réfléchir) tout en étant précis (toujours choisir les bons experts). C'est un peu comme le répartiteur d'un centre d'appels des urgences qui doit à la fois envoyer les bonnes équipes sans attendre, mais surtout s'assurer d'envoyer les bons spécialistes pour chaque type d'intervention.
Les avantages du Mixture of Experts
L'architecture MoE présente plusieurs avantages significatifs par rapport aux modèles traditionnels :
- Efficacité computationnelle : Malgré leur taille théorique énorme, les modèles MoE n'activent qu'une petite partie de leurs paramètres pour chaque tâche, réduisant ainsi les besoins en calcul.
- Spécialisation : Chaque expert peut se spécialiser dans des domaines spécifiques, améliorant ainsi la performance globale du modèle.
- Scalabilité : Il est plus facile d'ajouter de nouveaux experts spécialisés sans nécessiter un réentraînement complet du modèle.
- Flexibilité : L'architecture peut s'adapter à des tâches très diverses en activant différents combinaisons d'experts.
Les défis à relever
Malgré ses avantages, l'architecture MoE présente plusieurs défis techniques :
- Complexité d'entraînement : L'entraînement des modèles MoE est plus complexe que celui des modèles denses traditionnels. Il nécessite des techniques spécifiques pour équilibrer la charge entre les experts et éviter que certains ne soient jamais sélectionnés.
- Problèmes de routage : Un routage inefficace peut détériorer les performances. Si les mauvais experts sont sélectionnés, la qualité des réponses en souffrira.
- Coûts mémoire : Bien que le modèle soit économique lorsqu'il répond, il a besoin de garder tous ses experts "disponibles" en permanence. C'est comme une immense bibliothèque où vous ne consultez que quelques livres à la fois, mais où vous devez quand même trouver de la place pour toutes les étagères.
Pour les très grands modèles, ce besoin de "stockage" devient un vrai casse-tête : cela demande des ordinateurs ultra-puissants avec énormément de mémoire, ce qui peut rapidement devenir très coûteux et compliqué à gérer. - Instabilité : Les modèles MoE peuvent parfois être instables pendant l'entraînement, nécessitant des techniques de régularisation avancées.
Les modèles MoE célèbres
Plusieurs modèles notables utilisent aujourd'hui l'architecture MoE :
| Modèle | Année | Développeur | Caractéristiques principales |
|---|---|---|---|
| Mixtral 8x7B | 2023 | Mistral AI | Combine 8 experts de 7 milliards de paramètres chacun, mais n'en active que 2 à la fois. Performances comparables à des modèles beaucoup plus grands. |
| GPT-4 | 2023 | OpenAI | Architecture MoE non officiellement confirmée mais largement suspectée, expliquant ses performances exceptionnelles malgré sa taille. |
| Switch Transformers | 2021 | Démonstration de l'application à grande échelle de l'architecture MoE pour le traitement du langage naturel. | |
| GLaM (Generalist Language Model) | 2021 | Modèle de 1.2 billion de paramètres utilisant une architecture MoE. Performances supérieures à GPT-3 avec une meilleure efficacité de calcul. |
L'avenir du Mixture of Experts
L'architecture Mixture of Experts est l'une des voies passionnantes qu'explore l'intelligence artificielle aujourd'hui. À côté des modèles classiques comme les Transformers ou les réseaux de neurones traditionnels, l'architecture MoE apporte une solution originale et efficace pour gérer des systèmes toujours plus complexes.
Mais attention, ce n'est pas la seule approche ! D'autres chercheurs misent sur des modèles plus simples et plus économes en énergie, ou sur des architectures complètement nouvelles. Alors qui aura raison ? Peut-être que la meilleure solution sera de combiner plusieurs approches, comme on assemble des pièces d'un puzzle.
Sources
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
L'article fondateur de Google sur l'architecture MoE à grande échelle. - Mixtral of Experts
Annonce officielle du modèle Mixtral 8x7B par Mistral AI. - GLaM: Generalist Language Model
Présentation du modèle GLaM par Google. - Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Article de recherche sur les Switch Transformers.
Qu'est-ce que l'architecture Mixture of Experts (MoE) ?
Le Mixture of Experts est une architecture de réseau neuronal qui divise le travail entre plusieurs "experts" spécialisés. Pour chaque requête, un système de routage sélectionne uniquement les experts les plus pertinents, permettant ainsi de créer des modèles massifs sans exploser les coûts de calcul.
Quels sont les avantages du Mixture of Experts en IA ?
Les principaux avantages du MoE sont : une efficacité computationnelle accrue (seuls quelques experts sont activés par requête), la spécialisation des experts dans des domaines spécifiques, une meilleure scalabilité et une flexibilité pour s'adapter à des tâches diverses.
Quels modèles d'IA utilisent l'architecture MoE ?
Plusieurs modèles célèbres utilisent l'architecture MoE, dont Mixtral 8x7B de Mistral AI, GPT-4 (selon de nombreuses sources), les Switch Transformers de Google, et GLaM (Generalist Language Model) également développé par Google.
Comment fonctionne le routage dans une architecture MoE ?
Le routage dans une architecture MoE est assuré par un réseau de gating qui analyse l'entrée et détermine quels experts sont les plus compétents pour traiter la requête. Il attribue également un poids à chaque expert sélectionné. Les algorithmes de routage modernes utilisent généralement un mécanisme d'attention soft pour déterminer la pertinence de chaque expert.
Quels sont les défis de l'architecture MoE ?
Les principaux défis du MoE incluent : la complexité d'entraînement (nécessitant des techniques spécifiques pour équilibrer la charge), les problèmes de routage (un mauvais routage détériore les performances), les coûts mémoire (tous les experts doivent être stockés) et l'instabilité pendant l'entraînement.




