
Enquête : Ces médias qui empêchent l'IA d'accéder à leur contenu
Derrière le boom de l'intelligence artificielle se cache une bataille silencieuse mais cruciale : celle de l'accès au contenu. De plus en plus de médias prestigieux, du New York Times à The Guardian, ont décidé de bloquer les robots d'IA qui tentent de collecter le contenu de leurs articles.
Cette résistance organisée redéfinit les rapports entre journalisme et technologie, elle pose aussi une question fondamentale, celle de la monétisation du contenu à l'heure de l'IA.
Cette confrontation entre géants n'est pas qu'une simple bataille technique, c'est la mise en place d'un nouveau rapport de force sur fond de propriété intellectuelle.
Le phénomène : une barrière numérique contre l'IA
Depuis 2023, une tendance de fond s'est accélérée : les médias traditionnels n'acceptent plus que leur contenu soit utilisé sans consentement pour entraîner des modèles d'IA. Cette réaction s'organise à plusieurs niveaux :
- Modification technique des sites pour interdire l'accès à certains robots, pour bloquer ce qu'on appelle les "crawlers": des robots qui viennent parcourir les pages
- Mise à jour des conditions d'utilisation interdisant l'exploitation à des fins d'entraînement
- Actions en justice contre les entreprises technologiques
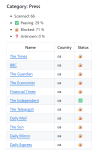
Le phénomène des sites web bloquant l'accès aux robots IA prend une ampleur considérable, comme en témoigne le projet collaboratif The Great GPT Firewall sur GitHub. Maintenu par la communauté, ce projet dresse la liste des sites qui bloquent les robots des principales IA.
Ce qui est particulièrement révélateur dans ce projet, c'est la diversité des sites qui adoptent cette approche. On y trouve non seulement des médias prestigieux comme Le Monde ou The Times, mais aussi des sites artistiques, des plateformes éducatives, et même des services gouvernementaux. Cette tendance démontre une prise de conscience croissante à travers différents secteurs de la nécessité de protéger le contenu numérique.
L'analyse des données montre également une accélération significative du phénomène depuis 2023, correspondant à la démocratisation des outils d'IA générative. Cette résistance n'est plus l'apanage de quelques acteurs isolés, mais bien un mouvement de fond.
Les acteurs clés : qui bloque l'accès et pourquoi ?
Parmi les médias ayant pris position, plusieurs noms se détachent par leur influence et leur détermination :
Le New York Times a été l'un des premiers à agir de manière décisive. En août 2023, le quotidien américain a mis à jour ses conditions d'utilisation pour interdire explicitement l'utilisation de son contenu pour entraîner des systèmes d'IA. En décembre 2023, il a franchi une étape supplémentaire en poursuivant OpenAI et Microsoft en justice pour violation de droits d'auteur.
The Guardian a suivi une voie similaire en septembre 2023, bloquant le crawler GPTBot d'OpenAI. Le journal britannique a justifié sa décision en déclarant que "le scraping de propriété intellectuelle à des fins commerciales est contraire à nos conditions d'utilisation".
D'autres médias comme CNN, Reuters, le Washington Post ou Bloomberg ont également rejoint ce mouvement de résistance, créant une coalition informelle dans le milieu journalistique.
Les techniques de blocage mises en œuvre
Les médias disposent de plusieurs outils techniques pour empêcher l'accès des IA à leur contenu :
- Le fichier robots.txt : Un simple fichier texte qui indique aux robots d'indexation quelles parties d'un site ils peuvent ou ne peuvent pas explorer. De nombreux médias y ont ajouté des lignes spécifiques pour bloquer GPTBot, ChatGPT-User et autres crawlers d'IA.
- Le pare-feu et la détection comportementale : Des solutions plus avancées qui identifient et bloquent les robots en analysant leur comportement de navigation, même lorsqu'ils utilisent des user-agents génériques.
- Les restrictions légales : Comme l'a fait le NYT, la modification des conditions d'utilisation permet d'établir un cadre juridique clair interdisant l'utilisation non autorisée du contenu.
Les arguments des médias : protection vs innovation
Les médias qui bloquent l'accès des IA avancent plusieurs arguments fondamentaux pour justifier leur position :
- Protection de la propriété intellectuelle
Le journalisme de qualité représente un investissement considérable en temps, ressources et expertise. Les médias estiment que les entreprises d'IA utilisent ces contenus sans autorisation ni compensation, ce qui constitue une violation du droit d'auteur. - Concurrence déloyale
Comme l'argue le New York Times dans sa plainte, les outils d'IA comme ChatGPT peuvent générer du contenu qui "récite mot pour mot le contenu des médias, le résume de près, et imite leur style expressif", créant ainsi des produits de substitution qui concurrencent directement les médias originaux. - Impact économique
Cette utilisation non autorisée prive les médias de revenus essentiels : abonnements, licences, publicité et affiliations. Le NYT estime que cela "porte atteinte à leur relation avec les lecteurs et les prive de revenus". - Qualité et désinformation
Les médias soulignent également que les IA peuvent reproduire leur contenu tout en y ajoutant des erreurs (hallucinations), ce qui risque de nuire à leur réputation et de propager des informations inexactes.
La riposte du monde littéraire : l'affaire J.R.R. Martin
La résistance ne se limite pas aux médias traditionnels. En septembre 2023, l'auteur de fantasy J.R.R. Martin, a initié la création d'une coalition d'écrivains qui a poursuivi OpenAI pour violation de droits d'auteur. Cette affaire, distincte mais complémentaire à celle du NYT, allègue que l'entreprise a utilisé illégalement des milliers de livres pour entraîner ChatGPT.
Cette action en justice illustre l'élargissement du front de la résistance au-delà du journalisme, touchant l'ensemble de l'industrie créative. Elle pose une question cruciale : si les œuvres protégées par le droit d'auteur peuvent être utilisées sans compensation pour entraîner des IA, quel avenir pour les créateurs de contenu ?
L'autre facette : Reddit et le modèle de la licence
Face à cette vague de blocages, certains acteurs ont choisi une approche différente. En février 2023, Reddit a annoncé un partenariat majeur avec Google, évalué à environ 60 millions de dollars par an, pour autoriser l'utilisation de son contenu pour entraîner les modèles d'IA.
Cette décision, controversée, représente une alternative potentielle au conflit : plutôt que de bloquer l'accès, monétiser directement l'utilisation du contenu par les entreprises d'IA. Ce modèle pourrait inspirer d'autres plateformes et médias, proposant un compromis dans cette bataille pour le contenu numérique.
La réponse des entreprises d'IA : l'argument du fair use
Face à ces accusations, OpenAI et les autres entreprises d'IA défendent leur position avec des arguments tout aussi solides :
- La doctrine du fair use
OpenAI argue que l'utilisation de contenu pour entraîner des IA constitue une "utilisation équitable" (fair use), car elle est transformative et ne se substitue pas au marché original. Ils comparent souvent ce processus à la manière dont un humain apprend en lisant diverses sources. - Bénéfice pour la société
Les entreprises d'IA mettent en avant les avantages de leurs technologies pour la société, affirmant que les modèles entraînés sur des contenus de qualité comme ceux du NYT ou du Guardian produisent des résultats plus fiables et utiles. - Volonté de coopération
OpenAI affirme être ouvert à des accords de licence avec les éditeurs, comme ils l'ont déjà fait avec certains médias. Ils présentent leur technologie comme une opportunité pour les médias de toucher de nouveaux publics et de développer de nouvelles sources de revenus. - Protection de la vie privée
Dans le cadre de la plainte du NYT, OpenAI a récemment fait valoir que les demandes du journal concernant la préservation des données des utilisateurs "contredisent fondamentalement les engagements de confidentialité envers les utilisateurs".
L'affaire New York Times vs OpenAI : un procès test
La plainte du New York Times contre OpenAI et Microsoft, déposée en décembre 2023, est devenue le procès test de cette confrontation. En juillet 2025, l'affaire a connu des développements majeurs :
- Consolidation avec d'autres plaintes : L'affaire a été fusionnée avec d'autres actions similaires dans "OpenAI Copyright Infringement Litigation".
- Victoire partielle du NYT : En mars 2025, le juge Sidney Stein a rejeté la majorité de la motion de rejet d'OpenAI, permettant aux principales allégations de violation de droit d'auteur du NYT de poursuivre.
- Bataille sur la préservation des données : En mai 2025, la cour a ordonné à OpenAI de conserver toutes les données des utilisateurs de ChatGPT indéfiniment, ce qu'OpenAI a contesté en invoquant la protection de la vie privée.
Ce procès pourrait définir des précédents juridiques cruciaux pour l'avenir de l'IA et du droit d'auteur, avec des implications qui dépassent largement le secteur des médias.
Implications et scénarios pour l'avenir
Cette confrontation entre médias et IA pourrait évoluer vers plusieurs scénarios :
- Le modèle de la licence
Une voie de compromis où les entreprises d'IA paieraient des licences pour utiliser le contenu des médias, similaire aux accords existants entre plateformes musicales et artistes. - La fragmentation du web
Un scénario plus sombre où le web se diviserait entre un "open web" accessible aux IA et un "walled garden" de contenu premium protégé, créant une fracture informationnelle. - L'intervention réglementaire
Les gouvernements pourraient intervenir pour établir un cadre juridique clair définissant les droits et obligations de chaque partie, comme le suggèrent certaines initiatives en Europe et aux États-Unis. - La coexistence innovante
Une solution où les médias développent leurs propres outils d'IA ou des partenariats stratégiques avec les entreprises technologiques, créant de nouveaux modèles économiques.
Quelle que soit l'issue, cette confrontation redéfinit fondamentalement la valeur du contenu journalistique et pourrait bien déterminer comment l'information sera produite, distribuée et monétisée dans les décennies à venir.
Sources
- The New York Times blocks OpenAI's web crawler - The Verge
Analyse du blocage du crawler OpenAI par le NYT et ses implications. - The Guardian blocks ChatGPT owner OpenAI from trawling its content - The Guardian
Annonce officielle du Guardian sur son blocage d'OpenAI. - How we're responding to The New York Times' data demands - OpenAI
Réponse officielle d'OpenAI concernant la préservation des données dans le cadre de la plainte du NYT.
Pourquoi les médias bloquent-ils l'accès des IA à leur contenu ?
Les médias bloquent l'accès des IA principalement pour protéger leur propriété intellectuelle, éviter la concurrence déloyale, préserver leurs revenus et empêcher la diffusion potentielle de désinformation à travers leurs contenus reproduits avec des erreurs.
Quels médias ont bloqué l'accès des crawlers IA ?
Parmi les médias notables ayant bloqué les crawlers IA figurent le New York Times, The Guardian, CNN, Reuters, le Washington Post, Bloomberg et de nombreux autres journaux prestigieux qui ont ajouté des restrictions à leur fichier robots.txt.
Comment les médias bloquent-ils techniquement l'accès des IA ?
Les médias utilisent plusieurs techniques : modification du fichier robots.txt pour bloquer spécifiquement les crawlers d'IA, mise en place de pare-feux et systèmes de détection comportementale, et mise à jour des conditions d'utilisation pour interdire l'exploitation à des fins d'entraînement.
Quelle est la position d'OpenAI face au blocage de ses robots par certains médias ?
OpenAI défend la doctrine du fair use, arguant que l'utilisation de contenu pour entraîner des IA est transformative et bénéfique pour la société. L'entreprise affirme être ouverte à des accords de licence avec les éditeurs, comme son partenariat avec Reddit, et s'inquiète des implications pour la vie privée des utilisateurs dans le cadre des procédures judiciaires.
Où en est la plainte du New York Times contre OpenAI ?
En juillet 2025, la plainte du NYT contre OpenAI et Microsoft est en cours. Le juge a rejeté la majorité de la motion de rejet d'OpenAI en mars 2025, permettant aux principales allégations de poursuivre. L'affaire a été consolidée avec d'autres plaintes similaires et une bataille juridique se poursuit concernant la préservation des données utilisateurs.





